註:本文同步更新在Notion!(數學公式會比較好閱讀)
注意力模型是現代深度學習中最具革命性的發展之一,特別是在自然語言處理(NLP)和計算機視覺領域中。它的核心理念是讓模型學會「關注」輸入數據的關鍵部分,而不是均勻地處理所有信息。這一機制極大提升了模型處理長序列數據的能力,並成為變壓器模型(Transformer)等架構的基石。
在處理序列數據時,例如句子或圖像,模型常常需要根據當前的上下文動態選擇某些重要信息,而不是一視同仁地對待所有輸入。注意力機制通過為每個輸入分配一個「權重」來決定它的重要性。這些權重表示模型應該「關注」哪部分數據,以便在給定的上下文中生成更準確的輸出。
注意力機制的基本組成包括三個向量:
計算每個鍵和查詢之間的匹配程度,這個匹配分數通常表示為兩個向量的點積:

注意力分數計算完後,通過 softmax 函數將其轉換為權重,使得所有權重的總和為 1。這樣能夠更直觀地表示模型應該多大程度上「關注」某個特徵:
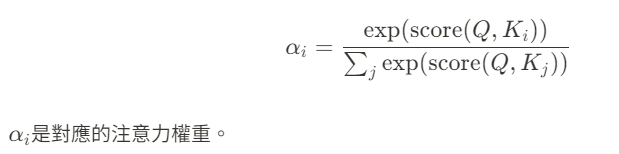

加權和的過程就是注意力機制能夠自動選擇重要信息的方式。
這是最基本的形式,直接通過查詢和鍵的點積來計算注意力分數,並應用 softmax 函數生成權重。這種方法計算量小,適合大部分應用。
當查詢和鍵向量的維度變得很大時,點積的值會變得很大,這可能會導致梯度消失或梯度爆炸問題。因此,在變壓器模型中,通常會將點積結果除以查詢向量的維度平方根來進行縮放:

多頭注意力機制是變壓器模型中的一個重要組成部分,它通過多個注意力機制的並行運行來提升模型的表達能力。每個「頭」都學習到不同的表示方式,這讓模型能夠同時關注數據的不同部分:
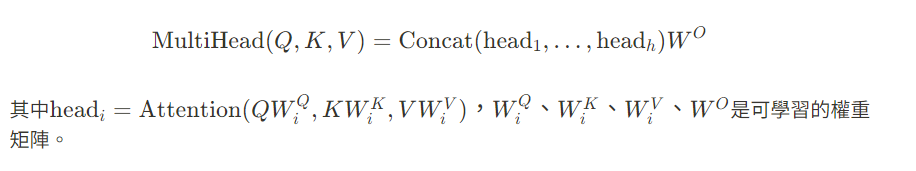
注意力機制為神經網路提供了一個「自適應權重」的機制,使模型能夠根據輸入數據的特徵動態地調整其內部的注意力模式。這種自適應性極大提升了模型的表達能力,特別是在需要處理變長序列或高度結構化數據的情境下。
注意力機制通過其動態調整權重的能力,使得深度學習模型能夠更加靈活地處理各種復雜的任務。隨著變壓器等模型的出現,注意力機制已經成為深度學習的核心工具之一,並在多個領域中展現出強大的應用潛力。

